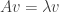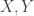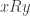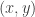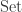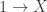Hilbert spaces are a particularly nice class of Banach spaces. They axiomatize ideas from Euclidean geometry such as orthogonality, projection, and the Pythagorean theorem, but the ideas apply to many infinite-dimensional spaces of functions of interest to various branches of mathematics. Hilbert spaces are also fundamental to quantum mechanics, as vectors in Hilbert spaces (up to phase) describe (pure) states of quantum systems.
Today we’ll develop and discuss some of the basic theory of Hilbert spaces. As with the theory of Banach spaces, there are (at least) two types of morphisms we might want to talk about (unitary operators and bounded operators), and we will discuss an elegant formalism that allows us to talk about both. Things written by John Baez will be cited excessively.
Definition and introductory remarks
Let ![V]() be a vector space over
be a vector space over ![k = \mathbb{R}]() or
or ![k = \mathbb{C}]() . An inner product on
. An inner product on ![V]() is a map
is a map ![\langle -, - \rangle : V \times V \to k]() satisfying
satisfying
![\langle x, ay + bz \rangle = a \langle x, y \rangle + b \langle x, z \rangle]() (linearity in the second argument),
(linearity in the second argument),
![\langle x, y \rangle = \overline{ \langle y, x \rangle }]() (conjugate symmetry; this implies conjugate linearity in the first argument),
(conjugate symmetry; this implies conjugate linearity in the first argument),
![\langle x, x \rangle \ge 0]() and
and ![\langle x, x \rangle = 0 \Rightarrow x = 0]() (positive-definiteness).
(positive-definiteness).
(Linearity in the second variable is conventional in physics but in mathematics the convention is generally to have linearity in the first variable. We use the physics convention above for reasons explained in the next section.)
A vector space equipped with an inner product is an inner product space. Inner products generalize the ordinary dot product of vectors in ![\mathbb{R}^n]() , but the formalism applies to infinite-dimensional spaces such as various function spaces, allowing us to use geometric intuition from the former to understand the latter. In quantum mechanics, inner products are fundamental as they give rise to transition amplitudes (see for example the Born rule).
, but the formalism applies to infinite-dimensional spaces such as various function spaces, allowing us to use geometric intuition from the former to understand the latter. In quantum mechanics, inner products are fundamental as they give rise to transition amplitudes (see for example the Born rule).
Any inner product spaces gives rise to a function ![\| x \| = \sqrt{ \langle x, x \rangle }]() which is readily seen to satisfy all of the axioms of a norm with the possible exception of the triangle inequality, which we now prove.
which is readily seen to satisfy all of the axioms of a norm with the possible exception of the triangle inequality, which we now prove.
Cauchy-Schwarz inequality: let ![u, v]() be vectors in an inner product space. Then
be vectors in an inner product space. Then ![|\langle u, v \rangle| \le \| u\| \| v \|]() .
.
The Cauchy-Schwarz inequality can be proven in many ways (see for example Steele’s The Cauchy-Schwarz Master Class). Although it is stated here for an arbitrary inner product space, by restricting to the subspace generated by ![u]() and
and ![v]() we see that it is really a statement about
we see that it is really a statement about ![2]() -dimensional inner product spaces.
-dimensional inner product spaces.
Proof. Consider the quadratic polynomial
![\displaystyle \| u - vt \|^2 = \langle u - vt, u - vt \rangle = \| u \|^2 - 2t \text{Re}(\langle u, v \rangle) + \| v \|^2]() .
.
By positive-definiteness, it cannot be negative, so its discriminant cannot be positive. This gives
![\Delta = 4 \text{Re}(\langle u, v \rangle)^2 - 4 \| u \|^2 \| v \|^2 \le 0]()
and it follows that ![\text{Re}(\langle u, v \rangle) \le \| u \|^2 \| v \|^2]() . Multiplying
. Multiplying ![u]() by a complex number of absolute value
by a complex number of absolute value ![1]() does not change the RHS, and it can make the LHS real and non-negative, giving the desired inequality.
does not change the RHS, and it can make the LHS real and non-negative, giving the desired inequality. ![\Box]()
Corollary: ![\| u + v \| \le \| u \| + \| v \|]() .
.
Proof. By Cauchy-Schwarz,
![\| u + v \|^2 = \| u \|^2 + 2 \text{Re}(\langle u, v \rangle) + \| v \|^2 \le \| u \|^2 + 2 \| u \| \| v \| + \| v \|^2]() .
. ![\Box]()
Following the above, for an inner product ![\langle \cdot, \cdot \rangle]() we call
we call ![\| \cdot \|]() the induced norm.
the induced norm.
Corollary: For any inner product space ![V]() and any
and any ![v \in V]() , the map
, the map ![v \mapsto \langle u, v \rangle]() is a continuous linear functional of operator norm
is a continuous linear functional of operator norm ![\| u \|]() with respect to the induced norm.
with respect to the induced norm.
The identity ![\| u + v \|^2 = \| u \|^2 + 2 \text{Re}(\langle u, v \rangle) + \| v \|^2]() should be thought of an abstract form of the law of cosines. In particular, if
should be thought of an abstract form of the law of cosines. In particular, if ![\langle u, v \rangle = 0]() (
(![u, v]() are orthogonal), then the Pythagorean theorem
are orthogonal), then the Pythagorean theorem
![\displaystyle \| u + v \|^2 = \| u \|^2 + \| v \|^2]()
holds.
An inner product space ![V]() is a Hilbert space if it is complete with respect to the induced norm.
is a Hilbert space if it is complete with respect to the induced norm.
Example. For ![X]() any measure space with measure
any measure space with measure ![\mu]() , the space
, the space ![L^2(X)]() is a Hilbert space with inner product
is a Hilbert space with inner product
![\displaystyle \langle f, g \rangle = \int_X \overline{f(x)} g(x) \, d \mu]() .
.
Special cases include the spaces ![\ell^2(S)]() for a set
for a set ![S]() as in the Banach space examples; wehn
as in the Banach space examples; wehn ![S]() is finite and we work over the reals we recover Euclidean space with the usual inner product. In quantum mechanics, a fundamental example is
is finite and we work over the reals we recover Euclidean space with the usual inner product. In quantum mechanics, a fundamental example is ![X = \mathbb{R}^3]() with Lebesgue measure, as
with Lebesgue measure, as ![L^2(\mathbb{R}^3)]() is the space in which wave functions describing a particle in three spatial dimensions live. If
is the space in which wave functions describing a particle in three spatial dimensions live. If ![\mu]() is a probability measure we can think of
is a probability measure we can think of ![f, g]() as random variables, and if they happen to have expected value
as random variables, and if they happen to have expected value ![0]() then
then ![\langle f, g \rangle]() is their covariance.
is their covariance.
If ![V]() is a real inner product space with induced norm
is a real inner product space with induced norm ![\| v \|]() , then a straightforward computation shows that
, then a straightforward computation shows that
![\displaystyle \langle x, y \rangle = \frac{ \| x + y \|^2 - \| x - y \|^2 }{2}]()
and if ![V]() is a complex inner product space a somewhat more tedious computation shows that
is a complex inner product space a somewhat more tedious computation shows that
![\displaystyle \langle x, y \rangle = \frac{ \| x + y \|^2 - \| x - y \|^2 + i \| ix + y \|^2 - i \| ix - y \|^2}{4}]() .
.
In any case, we conclude that the inner product uniquely determined by the norm it induces. Thus being Hilbert is a property of a Banach space up to isometric isomorphism. We can even characterize the Banach spaces with this property in a fairly straightforward manner: they are precisely the ones with norms satisfying the parallelogram identity
![\displaystyle \| x + y \|^2 + \| x - y \|^2 = 2 \| x\|^2 + 2 \| y \|^2]() .
.
This is fairly annoying to prove, but it has a nice interpretation: if a norm is like the Euclidean norm in this particular respect, then it must be like the Euclidean norm in various other respects (coming from what can be proven using the inner product space axioms).
We might now be tempted to think of Hilbert spaces as a subcategory of ![\text{Ban}_1]() , but we shouldn’t. For example, the product or coproduct of Hilbert spaces in
, but we shouldn’t. For example, the product or coproduct of Hilbert spaces in ![\text{Ban}_1]() is almost never a Hilbert space; Hilbert spaces instead admit a direct sum coming from a generalized
is almost never a Hilbert space; Hilbert spaces instead admit a direct sum coming from a generalized ![\ell^2]() -norm rather than a generalized
-norm rather than a generalized ![\ell^1]() – or
– or ![\ell^{\infty}]() -norm. This suggests that weak contractions aren’t a natural choice of morphisms between Hilbert spaces.
-norm. This suggests that weak contractions aren’t a natural choice of morphisms between Hilbert spaces.
If we want to be permissive, we should take bounded linear operators as morphisms. If we want to be restrictive, we want all of the relevant structure to be preserved (namely the inner product), so we could take as morphisms maps ![U : H_1 \to H_2]() such that
such that
![\langle v, w \rangle_{H_1} = \langle U(v), U(w) \rangle_{H_2}]() .
.
These include the unitary maps, which are the invertible maps with this property.
(Note that since the inner product is uniquely determined by a composition of linear functions and the norm, it follows that a linear operator between Hilbert spaces preserves the inner product if and only if it preserves the norm. Thus we may call a map satisfying the above property an isometry.)
We also make the following observation whose name will be explained below.
The Yoneda lemma for inner product spaces: Let ![u, v]() be vectors in an inner product space such that
be vectors in an inner product space such that ![\langle u, \cdot \rangle = \langle v, \cdot \rangle]() . Then
. Then ![u = v]() .
.
Proof. The above implies ![\langle u-v, \cdot \rangle = 0]() , so
, so ![\|u - v \| = 0]() , so
, so ![u = v]() by positive-definiteness.
by positive-definiteness. ![\Box]()
2-Hilbert spaces
The theory of real Hilbert spaces is a straightforward axiomatization of the properties of the dot product in Euclidean space, but the theory of complex Hilbert spaces includes an additional wrinkle, namely the issue of conjugate symmetry and the fact that the inner product is conjugate-linear rather than linear in one variable. Above I chose to have inner products be linear in the second variable rather than the first, and the reason is the following example.
Let ![G]() be a finite group and consider the category
be a finite group and consider the category ![\text{Rep}(G)]() of finite-dimensional complex representations of
of finite-dimensional complex representations of ![G]() . For
. For ![V, W \in \text{Rep}(G)]() with characters
with characters ![\chi_V, \chi_W]() , recall that we have
, recall that we have
![\displaystyle \dim \text{Hom}_G(V, W) = \frac{1}{|G|} \sum_{g \in G} \overline{\chi_V(g)} \chi_W(g)]() .
.
In other words, the dimension of spaces of intertwining operators defines an inner product on the complex vector space spanned by characters (formally, the tensor product ![\mathbb{C} \otimes K(\text{Rep}(G))]() where
where ![K]() denotes the Grothendieck group) which is naturally conjugate-linear in the first variable. Morally this is because Hom is contravariant in the first variable and covariant in the second.
denotes the Grothendieck group) which is naturally conjugate-linear in the first variable. Morally this is because Hom is contravariant in the first variable and covariant in the second.
This example is particularly interesting because in quantum mechanics the inner product of states describes the transition amplitude between them (in a sense that I don’t completely understand), and it would not be too far-fetched to think of transition amplitudes as being morphisms in some vague sense between states.
In this way we see that ![\text{Rep}(G)]() itself is a kind of categorified Hilbert space, with morphisms as a kind of categorified inner product. Decategorifying the Yoneda lemma for elements of
itself is a kind of categorified Hilbert space, with morphisms as a kind of categorified inner product. Decategorifying the Yoneda lemma for elements of ![\text{Rep}(G)]() gives back the Yoneda lemma for inner products above. Decategorifying the isomorphism
gives back the Yoneda lemma for inner products above. Decategorifying the isomorphism ![(V \Rightarrow W)^{\ast} \cong (W \Rightarrow V)]() gives conjugate-symmetry. Decategorifying the adjunction between, say, restriction and induction functors gives adjoint operators (see below). And so forth. For a further elaboration on this theme, see Baez’s Higher-Dimensional Algebra II: 2-Hilbert spaces.
gives conjugate-symmetry. Decategorifying the adjunction between, say, restriction and induction functors gives adjoint operators (see below). And so forth. For a further elaboration on this theme, see Baez’s Higher-Dimensional Algebra II: 2-Hilbert spaces.
Projections and complements
In ![\mathbb{R}^n]() , the ordinary dot product allows us to define the projection
, the ordinary dot product allows us to define the projection
![\displaystyle P_u(v) = \frac{ \langle u, v \rangle }{ \langle u, u \rangle } u]()
of a vector ![v]() onto another vector
onto another vector ![u]() . The above notation is somewhat confusing, as it takes two vectors as inputs when it should really take as input a vector
. The above notation is somewhat confusing, as it takes two vectors as inputs when it should really take as input a vector ![v]() and a subspace
and a subspace ![W]() ; the projection
; the projection ![P_W(v)]() should then be the closest vector in
should then be the closest vector in ![W]() to
to ![v]() . The above is just the special case that
. The above is just the special case that ![W = \text{span}(u)]() .
.
We formalize this as follows. For ![v \in V]() and
and ![S \subset V]() , define the distance
, define the distance
![d(v, S) = \inf_{s \in S} \| v - s \|]() .
.
(Of course this definition makes sense in any metric space.) Then ![s \in S]() is a closest vector in
is a closest vector in ![S]() to
to ![v]() if
if ![\| v - s \| = d(v, S)]() . We say that
. We say that ![S]() admits closest vectors if such a vector always exists for all
admits closest vectors if such a vector always exists for all ![v \in V]() . (Note that such a subset is in particular closed.)
. (Note that such a subset is in particular closed.)
For general subsets ![S]() , closest vectors are not guaranteed to be unique. However:
, closest vectors are not guaranteed to be unique. However:
Proposition: Let ![S]() be a subset of an inner product space
be a subset of an inner product space ![V]() which is closed under taking midpoints. Then the closest vector
which is closed under taking midpoints. Then the closest vector ![s \in S]() to a vector
to a vector ![v \in V]() is unique if it exists.
is unique if it exists.
Proof. Suppose that ![s_1, s_2]() are two closest vectors. By the parallelogram identity,
are two closest vectors. By the parallelogram identity,
![\displaystyle \left\| v - \frac{s_1 + s_2}{2} \right\|^2 + \left\| \frac{s_1 - s_2}{2} \right\|^2 = \frac{\| v - s_1 \|^2 + \| v - s_2 \|^2}{2}]() .
.
It follows that ![\frac{s_1 + s_2}{2}]() (which lies in
(which lies in ![S]() by assumption) is strictly closer to
by assumption) is strictly closer to ![v]() than either
than either ![s_1]() or
or ![s_2]() unless
unless ![\| s_1 - s_2 \| = 0]() , hence unless
, hence unless ![s_1 = s_2]() .
. ![\Box]()
Note that this is badly false in a general normed space. For example, in ![\mathbb{R}^2]() with the
with the ![\ell^{\infty}]() norm, every vector
norm, every vector ![(0, y), |y| \le 1]() is closest among the vectors on the
is closest among the vectors on the ![y]() -axis to the vector
-axis to the vector ![(1, 0)]() .
.
In Euclidean space, projection is valuable among other things because it resolves a vector into two perpendicular components. The same is true in arbitrary inner product spaces.
Proposition: Let ![S]() be a subset of an inner product space
be a subset of an inner product space ![V]() which is closed under scalar multiplication. If the closest vector
which is closed under scalar multiplication. If the closest vector ![s \in S]() to a vector
to a vector ![v \in V]() exists, then
exists, then ![\langle s, v-s \rangle = 0]() .
.
Proof. By multiplying by a suitable unit complex number as necessary we may assume WLOG that ![\langle s, v-s \rangle]() is real. Since
is real. Since ![s]() is closest, the real function
is closest, the real function ![t \mapsto \langle v - ts \rangle^2]() has a local minimum at
has a local minimum at ![t = 1]() . Its derivative there is therefore
. Its derivative there is therefore
![\displaystyle \left( \langle -s, v - ts \rangle + \langle v - ts, s \rangle \right)_{t=1} = - 2 \text{Re}(\langle s, v - ts \rangle) = 0]() .
. ![\Box]()
Let ![W]() be a subspace (necessarily closed) which admits closest vectors. Then it follows by the above that we may write any
be a subspace (necessarily closed) which admits closest vectors. Then it follows by the above that we may write any ![v \in V]() as a sum
as a sum
![v = w + (v-w)]()
of a vector in ![W]() and a vector in its orthogonal complement
and a vector in its orthogonal complement ![W^{\perp} = \{ v : \langle w, v \rangle = 0 \forall w \in W \}]() .
.
We now need to introduce some important terminology. If ![V, W]() are inner product spaces, their direct sum
are inner product spaces, their direct sum ![V \oplus W]() can be given the inner product
can be given the inner product
![\displaystyle \langle v_1 \oplus w_1, v_2 \oplus w_2 \rangle = \langle v_1, v_2 \rangle_{V} + \langle w_1, w_2 \rangle_W]() .
.
This defines the direct sum of inner product spaces. If an inner product space ![U]() has subspaces
has subspaces ![V, W]() such that
such that ![U]() is the internal direct sum of
is the internal direct sum of ![V, W]() as vector spaces and moreover such that
as vector spaces and moreover such that ![V, W]() are orthogonal, then
are orthogonal, then ![U]() is an internal direct sum of
is an internal direct sum of ![V, W]() as inner product spaces, which we write as
as inner product spaces, which we write as ![U = V \oplus W]() .
.
Proposition: Let ![W]() be a subspace of an inner product space
be a subspace of an inner product space ![V]() which admits closest vectors. Then
which admits closest vectors. Then ![V = W \oplus W^{\perp}]() .
.
Proof. By assumption, every ![v \in V]() can be written as
can be written as ![v = w + (v-w)]() where
where ![w \in W, (v-w) \in W^{\perp}]() . Since
. Since ![W \cap W^{\perp} = 0]() , this sum decomposition is necessarily unique, which already implies that it must be linear. Since
, this sum decomposition is necessarily unique, which already implies that it must be linear. Since ![W^{\perp}]() is orthogonal to
is orthogonal to ![W]() by assumption,
by assumption, ![V]() has the direct sum inner product.
has the direct sum inner product. ![\Box]()
We can reformulate the above geometric discussion algebraically in terms of axioms that the map ![v \mapsto w]() satisfies as follows. A projection on an inner product space
satisfies as follows. A projection on an inner product space ![V]() is a bounded linear operator
is a bounded linear operator ![P : V \to V]() such that
such that
![P]() is idempotent (
is idempotent (![P^2 = P]() ), and
), and
![P]() is self-adjoint (
is self-adjoint (![\langle u, Pv \rangle = \langle Pu, v \rangle]() for all
for all ![u, v \in V]() ).
).
We recall the following general result on idempotents.
Proposition: Let ![M]() be a left
be a left ![R]() -module (
-module (![R]() a ring, not necessarily commutative) and
a ring, not necessarily commutative) and ![P : M \to M]() be an idempotent morphism of
be an idempotent morphism of ![R]() -modules. Then
-modules. Then ![M]() admits a direct sum decomposition
admits a direct sum decomposition
![\displaystyle M = PM \oplus (1-P)M = \text{im}(P) \oplus \text{ker}(P)]() .
.
Proof. We may write any ![m \in M]() as
as ![m = Pm + (1-P)m]() . Since
. Since ![P(1-P) = 0]() , we have
, we have ![(1-P)m \in \text{ker}(P)]() . Conversely, if
. Conversely, if ![m \in \text{ker}(P)]() then
then ![(1-P)m = m]() , so
, so ![(1-P)M = \text{ker}(P)]() . Since
. Since ![P^2 m = Pm]() ,
, ![P]() fixes any element of
fixes any element of ![\text{im}(P)]() , so
, so ![\text{im}(P) \cap \text{ker}(P) = 0]() . Finally, since
. Finally, since ![P]() is a morphism, its kernel and image are both submodules of
is a morphism, its kernel and image are both submodules of ![M]() .
. ![\Box]()
The converse is straightforward; hence studying idempotents in ![\text{End}_R(M)]() is equivalent to studying direct sum decompositions of
is equivalent to studying direct sum decompositions of ![M]() .
.
Applied to projections, we have the following.
Proposition: Let ![P]() be a projection on an inner product space
be a projection on an inner product space ![V]() . Then
. Then ![V]() admits a direct sum decomposition
admits a direct sum decomposition
![\displaystyle V = PV \oplus (1-P)V = \text{im}(P) \oplus \text{ker}(1-P)]() .
.
In particular, ![\text{ker}(1-P) = \text{im}(P)^{\perp}]() , so a projection is uniquely determined by its image.
, so a projection is uniquely determined by its image.
Proof. Everything follows from the last proposition except the last claim, which follows from self-adjointness:
![\forall v : \langle u, Pv \rangle = 0 \Leftrightarrow \forall v : \langle Pu, v \rangle = 0]() .
. ![\Box]()
The converse is again straightforward. Altogether we can summarize our discussion as follows.
Theorem: The following conditions on a subspace ![W]() of an inner product space
of an inner product space ![V]() are equivalent.
are equivalent.
![W]() admits closest vectors.
admits closest vectors.
![V = W \oplus W^{\perp}]() .
.
- There exists a projection
![P]() such that
such that ![\text{im}(P) = W]() .
.
We turn now to the question of which subspaces have this property.
Proposition: Let ![W]() be a finite-dimensional subspace of an inner product space
be a finite-dimensional subspace of an inner product space ![V]() . Then
. Then ![W]() admits closest vectors.
admits closest vectors.
Proof. Let ![v \in V]() . We want to show that there is a closest vector in
. We want to show that there is a closest vector in ![W]() to
to ![V]() . Since
. Since ![0 \in W]() is at a distance
is at a distance ![\| v \|]() from
from ![v]() , it follows by the triangle inequality that the closest vector, if it exists, is necessarily contained in the closed ball of radius
, it follows by the triangle inequality that the closest vector, if it exists, is necessarily contained in the closed ball of radius ![2 \| v \|]() centered at the origin in
centered at the origin in ![W]() . Since
. Since ![W]() is finite-dimensional, this ball is compact, so the function
is finite-dimensional, this ball is compact, so the function ![w \mapsto \| v - w \|]() attains its minimum.
attains its minimum. ![\Box]()
This proof does not generalize to the infinite-dimensional case, since closed unit balls are no longer compact in this setting. By assuming that ![V]() is a Hilbert space, we can substitute completeness for compactness.
is a Hilbert space, we can substitute completeness for compactness.
Theorem: Let ![K]() be a closed convex subset of a Hilbert space
be a closed convex subset of a Hilbert space ![H]() . Then
. Then ![K]() admits a closest vector.
admits a closest vector.
Proof. One direction is straightforward. In the other direction, let ![v \in H]() be a vector and let
be a vector and let ![w_n \in W]() be a sequence such that
be a sequence such that
![\lim_{n \to \infty} \| v - w_n \| = d(v, W)]() .
.
By the parallelogram identity,
![\displaystyle \left\| v - \frac{w_n + w_m}{2} \right\|^2 + \left\| \frac{w_n - w_m}{2} \right\|^2 = \frac{\| v - w_n \|^2 + \| v - w_m \|^2}{2}]()
for any ![n, m]() (note that this is the same use of the parallelogram identity as when we proved that closest vectors are unique). The RHS approaches
(note that this is the same use of the parallelogram identity as when we proved that closest vectors are unique). The RHS approaches ![d(v, W)]() as
as ![n, m \to \infty]() while
while ![\| v - \frac{w_n + w_m}{2} \| \ge d(v, W)]() by definition, so it follows that
by definition, so it follows that ![\| w_n - w_m \| \to 0]() , hence that
, hence that ![w_n]() is a Cauchy sequence. Since
is a Cauchy sequence. Since ![H]() is a Hilbert space and
is a Hilbert space and ![W]() is closed,
is closed, ![w_n]() has a limit
has a limit ![w \in W]() satisfying
satisfying ![\| v - w \| = d(v, W)]() , hence this limit must be the closest vector.
, hence this limit must be the closest vector. ![\Box]()
Corollary: A subspace of a Hilbert space admits closest vectors if and only if it is closed.
Corollary: If ![V]() is a subspace of a Hilbert space
is a subspace of a Hilbert space ![H]() , then
, then ![V^{\perp \perp} = \overline{V}]() .
.
Proof. ![\overline{V}]() is a closed subspace of
is a closed subspace of ![H]() such that
such that ![\overline{V}^{\perp} = V^{\perp}]() , hence by the above we have a direct sum decomposition
, hence by the above we have a direct sum decomposition
![\displaystyle H = \overline{V} \oplus V^{\perp}]() .
.
In any direct sum decomposition the two spaces are orthogonal complements of each other, so it follows that ![\overline{V} = V^{\perp \perp}]() as desired.
as desired. ![\Box]()
Orthonormal bases
The theory of Banach spaces is unlike ordinary linear algebra in that Banach spaces do not admit a particularly good notion of basis. The linear-algebraic notion of basis, which only allows finite sums, is clearly unsuitable: it ignores the infinite sums which are now available, and spaces of functions don’t have reasonable Hamel bases anyway (see for example this math.SE question). The next obvious choice is to talk about Schauder bases, which are sequences ![e_i]() in a Banach space
in a Banach space ![B]() such that every
such that every ![v \in B]() has a unique representation as an infinite sum
has a unique representation as an infinite sum
![\displaystyle v = \sum c_i e_i]() .
.
Unlike ordinary bases, Schauder bases must be ordered since the sum above is not required to converge absolutely. They also don’t always exist, even for separable Banach spaces; there is a counterexample due to Enflo. Finally, as far as I can see there is no guarantee that the function sending a vector ![v]() to the coefficient
to the coefficient ![c_i]() above is even linear, let alone continuous, due to the lack of absolute convergence.
above is even linear, let alone continuous, due to the lack of absolute convergence.
But everything works out for Hilbert spaces. In any inner product space, a collection of vectors ![e_i]() is orthonormal if they satisfy
is orthonormal if they satisfy ![\langle e_i, e_j \rangle = \delta_{ij}]() . In particular, the
. In particular, the ![v_i]() have norm
have norm ![1]() and are linearly independent, since if
and are linearly independent, since if ![\sum c_i e_i = 0]() then
then ![\sum c_i \langle e_i, e_j \rangle = c_j = 0]() for all
for all ![j]() . An orthonormal basis of a Hilbert space
. An orthonormal basis of a Hilbert space ![H]() is an orthonormal set
is an orthonormal set ![e_i]() whose span is dense in
whose span is dense in ![H]() .
.
Bessel’s inequality: Let ![e_i]() be an orthonormal set and
be an orthonormal set and ![v]() a vector in an inner product space
a vector in an inner product space ![V]() . Then
. Then ![\langle e_i, v \rangle = 0]() for all but countably many
for all but countably many ![i]() , and
, and ![\| v \|^2 \ge \sum_i |\langle e_i, v \rangle|^2]() .
.
Proof. Let ![e_i]() be indexed by a set
be indexed by a set ![I]() and let
and let ![S]() be a finite subset of
be a finite subset of ![I]() . Let
. Let ![P_S]() be the projection onto
be the projection onto ![\text{span}(e_i : i \in S)]() . Then we may write
. Then we may write ![P_S]() explicitly as
explicitly as
![P_S v = \sum_{i \in S} \langle e_i, v \rangle e_i]()
by inspection. Since ![v = P_S v + (1-P_S)v]() , taking norms gives
, taking norms gives ![\| v \|^2 \ge \sum_{i \in S} |\langle e_i, v \rangle|^2]() for all finite subsets
for all finite subsets ![S]() . By exhausting every countable subset of
. By exhausting every countable subset of ![I]() by finite sets, it follows that the inequality holds for all countable subsets of
by finite sets, it follows that the inequality holds for all countable subsets of ![I]() . Because we cannot take uncountable sums of positive real numbers, it follows that
. Because we cannot take uncountable sums of positive real numbers, it follows that ![\langle e_i, v \rangle = 0]() for all but countably many
for all but countably many ![i]() , so the inequality holds for
, so the inequality holds for ![I]() .
. ![\Box]()
Bessel’s inequality becomes an equality in the following case, which is an infinite-dimensional generalization of the Pythagorean theorem.
Parseval’s identity: Let ![e_i]() be an at most countable orthonormal set. If
be an at most countable orthonormal set. If ![v = \sum c_i e_i]() converges, then it converges absolutely,
converges, then it converges absolutely, ![c_i = \langle e_i, v \rangle]() , and
, and ![\| v \|^2 = \sum |c_i|^2]() .
.
Proof. One direction is clear. In the other direction, let ![v_n = \sum_{i=1}^n c_i e_i]() , let
, let ![v = \lim_{n \to \infty} v_n]() . We have
. We have ![\| v \|^2 = \lim_{n \to \infty} \| v_n \|^2 = \lim_{n \to \infty} \sum_{i=1}^n |c_i|^2]() by assumption, so the sum converges absolutely. Convergence implies convergence of norms, hence
by assumption, so the sum converges absolutely. Convergence implies convergence of norms, hence ![\| v \|^2 = \sum |c_i|^2]() . Finally, since
. Finally, since ![c_i = \langle e_i, v_n \rangle]() for all
for all ![n \ge i]() , it follows by continuity that
, it follows by continuity that ![c_i = \langle e_i, v \rangle]() .
. ![\Box]()
We would like to conclude that orthonormal bases really are bases in a suitable Hilbert space sense, but first we need to prove the following.
Proposition: Let ![e_i]() be an orthonormal set and suppose that
be an orthonormal set and suppose that ![v]() lies in the closure of the span of the
lies in the closure of the span of the ![e_i]() . Then
. Then ![v = \sum \langle e_i, v \rangle e_i]() .
.
Proof. By the above, we may assume WLOG that ![e_i]() is countable, indexed
is countable, indexed ![e_1, e_2, ...]() . Let
. Let ![P_i]() be the projection onto
be the projection onto ![\text{span}(e_1, ... e_i)]() . Since
. Since ![P_i]() is the closest vector in
is the closest vector in ![\text{span}(e_1, ... e_i)]() to
to ![v]() , it follows that
, it follows that ![v]() lies in the closure of the span of the
lies in the closure of the span of the ![e_i]() if and only if
if and only if ![P_i v \to v]() .
. ![\Box]()
Corollary: Let ![H]() be a Hilbert space with an orthonormal basis
be a Hilbert space with an orthonormal basis ![e_i, i \in I]() . Then the map
. Then the map
![\displaystyle T: \ell^2(I) \ni (c_i) \mapsto \sum c_i e_i \in H]()
is a unitary isomorphism.
Proof. We showed above that ![T]() preserves norms, so it remains to prove that it is linear.
preserves norms, so it remains to prove that it is linear. ![T]() clearly respects scalar multiplication, and it also clearly respects addition on the subspace of
clearly respects scalar multiplication, and it also clearly respects addition on the subspace of ![\ell^2(I)]() consisting of sequences with finite support. Since
consisting of sequences with finite support. Since ![T]() preserves norms, the rest follows by the continuity of
preserves norms, the rest follows by the continuity of ![T]() and addition.
and addition. ![\Box]()
This is a strong structure theorem for Hilbert spaces with an orthonormal basis. We now turn our attention to proving that an orthonormal basis always exists. The idea, known as the Gram-Schmidt process, is the following in finitely many dimensions.
Suppose ![v_1, ... v_n]() are finitely many nonzero vectors in an inner product space. We’d like to find an orthonormal set of vectors
are finitely many nonzero vectors in an inner product space. We’d like to find an orthonormal set of vectors ![e_1, ... e_m]() with the same span. We’ll do this inductively. First, set
with the same span. We’ll do this inductively. First, set ![e_1 = \frac{v_1}{\| v_1 \|}]() . Assuming that
. Assuming that ![e_1, ... e_i]() have been defined, let
have been defined, let ![P_i]() denote the projection onto
denote the projection onto ![\text{span}(e_1, ... e_i)]() . Now, if
. Now, if ![j = j_i]() is the smallest index such that
is the smallest index such that ![v_j \not \in V_i]() , we can set
, we can set
![\displaystyle e_{i+1} = \frac{v_j - P_i(v_j)}{\| v_j - P_i(v_j) \|}.]()
It follows that ![e_1, ... e_i]() is an orthonormal basis of
is an orthonormal basis of ![v_1, ... v_{j_i}]() for all
for all ![i]() .
.
The Gram-Schmidt process as defined here extends without fuss to countably many vectors ![v_1, v_2, ...]() .
.
Corollary: Every separable Hilbert space has an orthonormal basis.
In particular, the separable infinite-dimensional Hilbert space is unique up to unitary isomorphism. Thus physicists sometimes speak of “Hilbert space” (as in “vectors in Hilbert space”) by which they mean the unique separable infinite-dimensional Hilbert space.
To extend the Gram-Schmidt process to an arbitrary number of vectors in a Hilbert space, we use transfinite induction. If you don’t care about non-separable Hilbert spaces, you can stop reading here.
Let ![v_{\alpha}]() be a collection of vectors in a Hilbert space indexed by ordinals and define a corresponding orthonormal set
be a collection of vectors in a Hilbert space indexed by ordinals and define a corresponding orthonormal set ![e_{\alpha}]() as follows. As above, we set
as follows. As above, we set ![e_1 = \frac{v_1}{\| v_1 \|}]() . If
. If ![e_{\alpha}]() has already been defined for all
has already been defined for all ![\alpha \le \beta]() , let
, let ![\gamma]() be the least ordinal such that
be the least ordinal such that ![v_{\gamma}]() is not contained in the closure of
is not contained in the closure of ![\text{span}(e_{\alpha} : \alpha \le \beta)]() , let
, let ![P_{\beta}]() be the projection onto this subspace, and define
be the projection onto this subspace, and define
![\displaystyle e_{\beta+1} = \frac{v_{\gamma} - P_{\beta} v_{\gamma}}{\| v_{\gamma} - P_{\beta} v_{\gamma} \|}]() .
.
Similarly, if ![e_{\alpha}]() has already been defined for all
has already been defined for all ![\alpha < \beta]() for
for ![\beta]() a limit ordinal, let
a limit ordinal, let ![v_{\gamma}]() be the least ordinal such that
be the least ordinal such that ![v_{\gamma}]() is not contained in the closure of
is not contained in the closure of ![\text{span}(e_{\alpha} : \alpha < \beta)]() , let
, let ![P_{<\beta}]() be the projection onto this subspace, and define
be the projection onto this subspace, and define
![\displaystyle e_{\beta} = \frac{v_{\gamma} - P_{<\beta} v_{\gamma}}{\| v_{\gamma} - P_{<\beta} v_{\gamma} \|}]() .
.
By transfinite induction the ![e_i]() are orthonormal and
are orthonormal and ![e_1, ... e_{\beta}]() is an orthonormal basis for
is an orthonormal basis for ![\text{span}(v_1, ... v_{\gamma})]() (where
(where ![\gamma]() is defined as above in relation to
is defined as above in relation to ![\beta]() ).
).
Corollary: Every Hilbert space has an orthonormal basis.
Unfortunately, this seems to require some form of choice. What we can prove in ZF is that every Hilbert space for which one can exhibit explicitly a dense well-ordered subset has an orthonormal basis.
Using orthonormal bases
Consider the Hilbert space ![H = L^2(S^1)]() where
where ![S^1]() carries normalized Haar measure. Equivalently, consider
carries normalized Haar measure. Equivalently, consider ![H = L^2([-\pi, \pi])]() with the inner product
with the inner product
![\displaystyle \langle f, g \rangle = \frac{1}{2\pi} \int_{-\pi}^{\pi} \overline{f(x)} g(x) \, dx]() .
.
The function ![f(x) = x]() separates points, so by Stone-Weierstrass the smallest algebra it contains which is closed under complex conjugation is dense in
separates points, so by Stone-Weierstrass the smallest algebra it contains which is closed under complex conjugation is dense in ![C([-\pi, \pi])]() in the uniform topology, hence in
in the uniform topology, hence in ![L^2]() . Since
. Since ![C([-\pi, \pi])]() is dense in
is dense in ![L^2([-\pi, \pi])]() , it follows that in fact the algebra of complex polynomials is dense in
, it follows that in fact the algebra of complex polynomials is dense in ![H]() . Consequently,
. Consequently, ![H]() is separable and has an orthonormal basis. The Gram-Schmidt process can be used to construct such a basis starting from the vectors
is separable and has an orthonormal basis. The Gram-Schmidt process can be used to construct such a basis starting from the vectors ![1, x, x^2, ...]() ; these are, up to some normalization, the Legendre polynomials.
; these are, up to some normalization, the Legendre polynomials.
Another orthonormal basis comes from the observation that ![f(x) = e^{ix}]() also separates points, so the span of the functions
also separates points, so the span of the functions ![e^{inx}, n \in \mathbb{Z}]() , is also dense by Stone-Weierstrass. Happily, these functions are already orthonormal: we have
, is also dense by Stone-Weierstrass. Happily, these functions are already orthonormal: we have
![\displaystyle \langle e^{inx}, e^{imx} \rangle = \frac{1}{2\pi} \int_{-\pi}^{\pi} e^{i(m-n)x} \, dx = \delta_{nm}]() .
.
It follows that we may expand any function in ![L^2]() in a Fourier series
in a Fourier series
![\displaystyle f(x) = \sum_{n \in \mathbb{Z}} \langle e^{inx}, f(x) \rangle e^{inx}]() .
.
We caution that what we have proven so far is only enough to conclude that Fourier series converge in ![L^2]() , which says nothing about uniform or pointwise convergence; these are much more subtle matters. However, even just
, which says nothing about uniform or pointwise convergence; these are much more subtle matters. However, even just ![L^2]() convergence is enough to prove some nontrivial results. For example, we compute using integration by parts that
convergence is enough to prove some nontrivial results. For example, we compute using integration by parts that
![\displaystyle \langle e^{inx}, x \rangle = \frac{1}{2\pi} \int_{-\pi}^{\pi} x e^{-inx} \, dx = \frac{(-1)^n i}{n}]()
if ![n \neq 0]() and
and ![\langle 1, x \rangle = 0]() since
since ![x]() is odd, hence
is odd, hence
![\displaystyle x = \sum_{n \neq 0} \frac{(-1)^n i e^{inx}}{n}]()
in ![H]() . Taking norms of both sides, we conclude
. Taking norms of both sides, we conclude
![\displaystyle \frac{\pi^2}{3} = 2 \sum_{n \ge 1} \frac{1}{n^2} = 2 \zeta(2)]() .
.
This is the answer to the famous Basel problem. Replacing ![x]() with
with ![x^k]() above gives us a method for evaluating
above gives us a method for evaluating ![\zeta(2k)]() for all positive integers
for all positive integers ![k]() .
.
Adjoints
The assignment ![v \mapsto \langle v, - \rangle]() defines an injection from any inner product space
defines an injection from any inner product space ![V]() to its dual space
to its dual space ![V^{\ast}]() (recall that this consists of bounded linear operators
(recall that this consists of bounded linear operators ![V \to k]() ). Moreover,
). Moreover, ![\langle v, - \rangle]() has norm
has norm ![\| v \|]() , so this injection is norm-preserving. However, it is conjugate-linear rather than linear. To fix this, we introduce for any complex vector space
, so this injection is norm-preserving. However, it is conjugate-linear rather than linear. To fix this, we introduce for any complex vector space ![V]() the conjugate
the conjugate ![\overline{V}]() (not to be confused with its closure in some ambient space!), which is the same abelian group as
(not to be confused with its closure in some ambient space!), which is the same abelian group as ![V]() but with scalar multiplication defined by the conjugate of scalar multiplication in
but with scalar multiplication defined by the conjugate of scalar multiplication in ![V]() . (This only matters if we work over
. (This only matters if we work over ![\mathbb{C}]() rather than over
rather than over ![\mathbb{R}]() .) Then the inner product on any inner product space defines a linear norm-preserving injection
.) Then the inner product on any inner product space defines a linear norm-preserving injection
![\overline{V} \ni v \mapsto \langle v, - \rangle \in V^{\ast}]() .
.
It is natural to ask when this map is an isomorphism (of normed vector spaces).
Riesz represenation: Let ![H]() be a Hilbert space. Then the map
be a Hilbert space. Then the map ![\overline{H} \to H^{\ast}]() above is an isomorphism.
above is an isomorphism.
Proof. We know that it is linear, injective, and norm-preserving, so it suffices to prove that it is surjective. Let ![\varphi : H \to k]() be a continuous linear functional. The claim is trivial if
be a continuous linear functional. The claim is trivial if ![\varphi]() is zero, so suppose
is zero, so suppose ![\varphi]() is nonzero.
is nonzero. ![\text{ker}(\varphi)]() is closed, so
is closed, so ![H]() admits a direct sum decomposition
admits a direct sum decomposition
![\displaystyle H = \text{ker}(\varphi) \oplus \text{ker}(\varphi)^{\perp}]() .
.
Since ![\varphi]() is nonzero,
is nonzero, ![\text{ker}(\varphi)^{\perp}]() is nontrivial, and if
is nontrivial, and if ![v, w \in \text{ker}(\varphi)^{\perp}]() then
then ![\varphi(w) v - \varphi(v) w \in \text{ker}(\varphi)]() , so it follows that
, so it follows that ![\text{ker}(\varphi)^{\perp}]() is one-dimensional. If
is one-dimensional. If ![u \in \text{ker}(\varphi)^{\perp}]() is any nonzero vector, then
is any nonzero vector, then ![\langle u, - \rangle]() is a continuous linear functional which is trivial in
is a continuous linear functional which is trivial in ![\text{ker}(\varphi)]() and nontrivial on its orthogonal complement, so must be equal to
and nontrivial on its orthogonal complement, so must be equal to ![\varphi]() up to a scalar.
up to a scalar.
The completeness of ![H]() is essential. For example, let
is essential. For example, let ![V]() be the space of compactly supported sequences
be the space of compactly supported sequences ![\mathbb{Z} \to \mathbb{C}]() with the inner product induced from
with the inner product induced from ![\ell^2(\mathbb{Z})]() . Then there is a continuous linear functional
. Then there is a continuous linear functional ![V \to \mathbb{C}]() sending such a sequence
sending such a sequence ![c_i]() to, say,
to, say, ![\sum \frac{c_i}{i^2 + 1}]() which is not of the form
which is not of the form ![\langle v, - \rangle]() for any
for any ![v \in V]() .
.
Corollary: Hilbert spaces are reflexive.
The Riesz representation theorem allows us to define the following crucial operation.
Theorem-Definition: let ![T : H_1 \to H_2]() be a bounded linear operator. There exists a unique map
be a bounded linear operator. There exists a unique map ![T^{\dagger} : H_2 \to H_1]() , the adjoint (or Hermitian adjoint) of
, the adjoint (or Hermitian adjoint) of ![T]() , which satisfies
, which satisfies
![\displaystyle \langle v, Tw \rangle_{H_2} = \langle T^{\dagger} v, w \rangle_{H_1} \forall v \in H_2, w \in H_1]() .
.
Proof. For fixed ![v]() the map
the map ![w \mapsto \langle v, Tw \rangle_{H_2}]() is a continuous linear functional on
is a continuous linear functional on ![H_1]() , so by Riesz representation there exists a unique vector
, so by Riesz representation there exists a unique vector ![T^{\dagger} v \in H_1]() such that
such that ![\langle v, Tw \rangle_{H_2} = \langle T^{\dagger} v, w \rangle_{H_1}]() for all
for all ![w]() . Moreover, by uniqueness
. Moreover, by uniqueness
![\langle u + cv, Tw \rangle_{H_2} = \langle T^{\dagger} u, Tw \rangle + \langle c T^{\dagger} v, Tw \rangle = \langle T^{\dagger}(u+cv), \langle w \rangle_{H_1}]()
so the assignment ![v \mapsto T^{\dagger} v]() is linear. Finally,
is linear. Finally,
![\displaystyle \| T \| = \sup_{|u|, |v| = 1} \langle u, Tv \rangle = \sup_{|u|, |v| = 1} \langle T^{\dagger} u, v \rangle = \| T^{\dagger} \|]()
so ![T^{\dagger}]() is bounded (in fact has the same norm as
is bounded (in fact has the same norm as ![T]() ).
). ![\Box]()
Remark. Let ![H_1 = H_2 = H]() and let
and let ![e_i]() be an orthonormal basis. Then
be an orthonormal basis. Then ![\langle e_i, T e_j \rangle = \langle T^{\dagger} e_i, e_j \rangle = \overline{ \langle e_j, T^{\dagger} e_i \rangle }]() , which says precisely that the “matrix” of
, which says precisely that the “matrix” of ![T^{\dagger}]() with respect to the basis
with respect to the basis ![e_i]() is the conjugate transpose of the “matrix” of
is the conjugate transpose of the “matrix” of ![T]() .
.
Remark. The adjoint is closely related, but not identical, to the dual ![T^{\ast}]() . If
. If ![B, C]() are any two Banach spaces, then for any bounded linear operator
are any two Banach spaces, then for any bounded linear operator ![T : B \to C]() we may define its dual
we may define its dual ![T^{\ast} : C^{\ast} \to B^{\ast}]() on dual spaces, which is defined by precomposition. It is a corollary of the Hahn-Banach theorem that
on dual spaces, which is defined by precomposition. It is a corollary of the Hahn-Banach theorem that ![\| T^{\ast} \| = \| T \|]() , but the above argument does not need the Hahn-Banach theorem. If
, but the above argument does not need the Hahn-Banach theorem. If ![B, C]() are Hilbert spaces, then
are Hilbert spaces, then ![T^{\ast}]() is a map
is a map ![C^{\ast} \to B^{\ast}]() , or equivalently by Riesz representation a map
, or equivalently by Riesz representation a map ![\overline{C} \to \overline{B}]() , whereas the adjoint is a map
, whereas the adjoint is a map ![C \to B]() , so it is important not to confuse the two as mathematical objects; however, one is essentially the complex conjugate of the other.
, so it is important not to confuse the two as mathematical objects; however, one is essentially the complex conjugate of the other.
The adjoint satisfies the following basic properties which follow straightforwardly from the definition. The second property shows that taking adjoints may be regarded as a generalization of complex conjugation for operators on Hilbert spaces.
![(S + T)^{\dagger} = S^{\dagger} + T^{\dagger}]() ,
,
![c^{\dagger} = \bar{c}]() (
(![c]() a scalar),
a scalar),
![(TS)^{\dagger} + S^{\dagger} T^{\dagger}]() ,
,
![T^{\dagger \dagger} = T]() .
.
The adjoint allows us to define the following important classes of linear operators. A bounded linear operator ![f : H \to H]() on a Hilbert space is
on a Hilbert space is
- self-adjoint if
![f^{\dagger} = f]() ,
,
- skew-adjoint if
![f^{\dagger} = -f]() ,
,
- unitary if
![f^{\dagger} = f^{-1}]() ,
,
- normal if
![f^{\dagger} f = f f^{\dagger}]() .
.
In quantum mechanics, self-adjoint operators play the role of real-valued observables. They should be thought of as the “real operators,” for example because their eigenvalues are necessarily real. Any operator can be written uniquely as the sum of a self-adjoint and skew-adjoint operator
![\displaystyle f = \frac{f + f^{\dagger}}{2} + \frac{f - f^{\dagger}}{2}]() .
.
Since ![T]() is self-adjoint if and only if
is self-adjoint if and only if ![iT]() is skew-adjoint, one can think of the above as a decomposition of an operator into its real and imaginary parts
is skew-adjoint, one can think of the above as a decomposition of an operator into its real and imaginary parts ![\text{Re}(f), \text{Im}(f)]() , although this is not particularly useful unless the two commute (which is the case if and only if
, although this is not particularly useful unless the two commute (which is the case if and only if ![f]() is normal). When that happens, if
is normal). When that happens, if ![v]() is an eigenvector of
is an eigenvector of ![f]() with eigenvalue
with eigenvalue ![\lambda]() , then
, then ![v]() is an eigenvector of
is an eigenvector of ![f^{\dagger}]() with eigenvalue
with eigenvalue ![\overline{\lambda}]() (we will prove this below), hence
(we will prove this below), hence ![v]() is an eigenvector of
is an eigenvector of ![\text{Re}(f)]() with eigenvalue
with eigenvalue ![\text{Re}(\lambda)]() and an eigenvector of
and an eigenvector of ![\text{Im}(f)]() with eigenvalue
with eigenvalue ![\text{Im}(\lambda)]() .
.
The unitary maps are precisely the invertible maps preserving the inner product. They form a group, the unitary group ![U(H)]() of
of ![H]() . A homomorphism
. A homomorphism ![G \to U(H)]() where
where ![G]() is a group is a unitary representation of
is a group is a unitary representation of ![G]() , and these are a very natural object of study. (See for example the Peter-Weyl theorem.)
, and these are a very natural object of study. (See for example the Peter-Weyl theorem.)
The skew-adjoint maps form a Lie algebra under commutator, the unitary Lie algebra ![\mathfrak{u}(H)]() . These are precisely the maps
. These are precisely the maps ![f]() such that
such that ![t \mapsto e^{ft}]() is a continuous group homomorphism
is a continuous group homomorphism ![\mathbb{R} \to U(H)]() . The proof is straightforward but we will defer it to the next post when it can be done in slightly greater generality.
. The proof is straightforward but we will defer it to the next post when it can be done in slightly greater generality.
The spectral theorem in finite dimensions
As a simple but important illustration of thinking in terms of adjoints, we prove the following.
Spectral theorem: Let ![A : H \to H]() be a self-adjoint operator on a finite-dimensional Hilbert space
be a self-adjoint operator on a finite-dimensional Hilbert space ![H]() . Then there exists an orthonormal basis of
. Then there exists an orthonormal basis of ![H]() consisting of eigenvectors of
consisting of eigenvectors of ![A]() , and all eigenvalues of
, and all eigenvalues of ![A]() are real.
are real.
Proof. The first step is to prove that ![A]() has an eigenvector. This is true for any linear transformation on a finite-dimensional complex vector space using, for example, standard facts about characteristic polynomials, but we will give an independent proof that more strongly suggests the correct generalization to the infinite-dimensional case.
has an eigenvector. This is true for any linear transformation on a finite-dimensional complex vector space using, for example, standard facts about characteristic polynomials, but we will give an independent proof that more strongly suggests the correct generalization to the infinite-dimensional case.
Let ![v \in H]() be a vector of norm
be a vector of norm ![1]() such that
such that
![\displaystyle \langle v, Av \rangle]()
is maximized. (Such a vector exists by compactness.) We claim that ![v]() is an eigenvector of
is an eigenvector of ![A]() . To see this, let
. To see this, let ![W = v^{\perp}]() and let
and let ![w \in W]() be a unit vector. Then
be a unit vector. Then ![v_{\theta} = (\cos \theta) v + (\sin \theta) w]() is a one-parameter family of unit vectors, and by assumption the function
is a one-parameter family of unit vectors, and by assumption the function ![\langle v_{\theta}, Av_{\theta} \rangle]() has a local maximum at
has a local maximum at ![\theta = 0]() . We compute that this is equal to
. We compute that this is equal to
![\langle (\cos^2 \theta) \langle v, Av \rangle + (\cos \theta \sin \theta)(\langle v, Aw \rangle + \langle w, Av \rangle) + (\sin^2 \theta) \langle w, Aw \rangle]() .
.
Its derivative at ![\theta = 0]() is equal to
is equal to
![\displaystyle \langle v, Aw \rangle + \langle w, Av \rangle = 2 \text{Re} \langle w, Av \rangle = 0]() .
.
Since we may scale ![v, w]() by unit complex numbers without loss of generality, it follows that
by unit complex numbers without loss of generality, it follows that ![\langle w, Av \rangle = 0]() for all
for all ![w \in \text{span}(v)^{\perp}]() , hence
, hence ![Av = \lambda v]() for some
for some ![\lambda]() . Since
. Since
![\lambda = \langle v, Av \rangle = \langle Av, v \rangle = \overline{\lambda}]()
it follows that ![\lambda]() is real. Finally, since
is real. Finally, since
![\displaystyle w \in W \Rightarrow \langle w, Av \rangle = 0 \Leftrightarrow \langle Aw, v \rangle = 0]()
it follows that ![W]() is an invariant subspace for
is an invariant subspace for ![A]() , so by induction we may complete
, so by induction we may complete ![v]() to an orthonormal basis of eigenvectors of
to an orthonormal basis of eigenvectors of ![A]() as desired.
as desired. ![\Box]()
An equivalent statement is that a self-adjoint operator is diagonalizable by a unitary operator. Since commuting operators act on each other’s eigenspaces, this is also true for normal operators (although the eigenvalues need no longer be real in this case). More generally, we can say the following.
Corollary: Let ![A_i, i \in I]() be a commuting family of normal operators on a finite-dimensional Hilbert space
be a commuting family of normal operators on a finite-dimensional Hilbert space ![H]() . Then there exists an orthonormal basis
. Then there exists an orthonormal basis ![e_1, ... e_n]() consisting of eigenvectors for all of the
consisting of eigenvectors for all of the ![A_i]() .
.
In other words, the ![A_i]() may be simultaneously diagonalized by a unitary operator.
may be simultaneously diagonalized by a unitary operator.
A geometric interpretation of the spectral theorem is the following. Working over ![\mathbb{R}]() for simplicity,
for simplicity, ![A]() is a self-adjoint operator if and only if the bilinear form
is a self-adjoint operator if and only if the bilinear form ![\langle w, Av \rangle]() is symmetric. Associated to such a bilinear form is the quadratic form
is symmetric. Associated to such a bilinear form is the quadratic form ![q(v) = \langle v, Av \rangle]() from which it may be recovered. The spectral theorem shows that, letting
from which it may be recovered. The spectral theorem shows that, letting ![e_1, ... e_n]() be an orthonormal basis and letting
be an orthonormal basis and letting ![\lambda_1, ... \lambda_n]() be the corresponding eigenvalues, we may write
be the corresponding eigenvalues, we may write
![\displaystyle q(\sum x_i e_i) = \sum \lambda_i x_i^2]() .
.
The “unit spheres” ![q(v) = 1]() then describe shapes in
then describe shapes in ![\mathbb{R}^n]() generalizing conic sections for
generalizing conic sections for ![n = 2]() depending on how many of the
depending on how many of the ![\lambda_i]() are positive, negative, or zero. For example, when
are positive, negative, or zero. For example, when ![n = 3]() we may get ellipsoids or hyperboloids.
we may get ellipsoids or hyperboloids. ![q]() is positive-definite if and only if all of the
is positive-definite if and only if all of the ![\lambda_i]() are positive, in which case
are positive, in which case ![q(v) = 1]() describes an ellipsoid. In this case the vectors
describes an ellipsoid. In this case the vectors ![e_i]() can be interpreted as the “principal axes” of the ellipsoid, which generalize the semimajor and semiminor axis from the case
can be interpreted as the “principal axes” of the ellipsoid, which generalize the semimajor and semiminor axis from the case ![n = 2]() , and the
, and the ![\lambda_i]() are the squares of the reciprocals of the lengths of these axes.
are the squares of the reciprocals of the lengths of these axes.
The dagger category of Hilbert spaces
The category ![\text{Hilb}]() of Hilbert spaces has as morphisms the bounded linear operators. Since two Hilbert spaces which are bi-Lipschitz equivalent have orthonormal bases of the same cardinality, they are actually isometrically (equivalently, unitarily) isomorphic, but not every bi-Lipschitz equivalence is an isometry. We still want to talk about unitary maps in this setting, so how should we do that?
of Hilbert spaces has as morphisms the bounded linear operators. Since two Hilbert spaces which are bi-Lipschitz equivalent have orthonormal bases of the same cardinality, they are actually isometrically (equivalently, unitarily) isomorphic, but not every bi-Lipschitz equivalence is an isometry. We still want to talk about unitary maps in this setting, so how should we do that?
The answer is to explicitly make the adjoint part of the structure of ![\text{Hilb}]() . We define a dagger category, or
. We define a dagger category, or ![^{\dagger}]() -category, to be a category
-category, to be a category ![C]() equipped with a contravariant functor
equipped with a contravariant functor
![^{\dagger} : C \to C]()
which is the identity on objects and which satisfies ![^{\dagger \dagger} = \text{id}_C]() . More explicitly, for every pair of objects
. More explicitly, for every pair of objects ![a, b \in C]() there is a map
there is a map
![\displaystyle \text{Hom}(a, b) \ni f \mapsto f^{\dagger} \in \text{Hom}(b, a)]()
such that ![(fg)^{\dagger} = g^{\dagger} f^{\dagger}]() and
and ![f^{\dagger \dagger} = f]() . In any dagger category, an endomorphism
. In any dagger category, an endomorphism ![f : a \to b]() is self-adjoint if
is self-adjoint if ![f^{\dagger} = f]() and an isomorphism
and an isomorphism ![f : a \to b]() is unitary if
is unitary if ![f^{\dagger} = f^{-1}]() . A functor
. A functor ![F : C : \to D]() between dagger categories is a dagger functor if
between dagger categories is a dagger functor if ![F(f^{\dagger}) = F(f)^{\dagger}]() .
.
Example. Let ![\text{Rel}]() denote the category of sets and relations. Recall that a relation
denote the category of sets and relations. Recall that a relation ![R]() between two sets
between two sets ![X, Y]() is a subset of their Cartesian product
is a subset of their Cartesian product ![X \times Y]() . We write
. We write ![xRy]() to mean that
to mean that ![(x, y)]() is in this subset. Composition of relations is defined as follows: if
is in this subset. Composition of relations is defined as follows: if ![R : X \to Y]() and
and ![S : Y \to Z]() are two relations, then
are two relations, then ![R \circ S : X \to Z]() is the relation defined by
is the relation defined by
![\displaystyle x (R \circ S) z \Leftrightarrow \exists y \in Y : x R y, y S z]() .
.
(Note that this disagrees with the usual convention for function composition, where a function ![f : X \to Y]() is realized as the relation
is realized as the relation ![(x, f(x))]() ; what I call
; what I call ![R \circ S]() would be for functions called
would be for functions called ![S \circ R]() .) For intuition, you should think of a relation between two sets as defining a partially defined and nondeterministic function between them (“nondeterministic” is another way to say “multivalued” but I think it gives a better intuition).
.) For intuition, you should think of a relation between two sets as defining a partially defined and nondeterministic function between them (“nondeterministic” is another way to say “multivalued” but I think it gives a better intuition).
![\text{Rel}]() is a dagger category with the dagger
is a dagger category with the dagger ![R^{\dagger} : Y \to X]() defined by
defined by
![\displaystyle y R^{\dagger} x \Leftrightarrow x R y]() .
.
A relation is self-adjoint if and only if it is symmetric, and every isomorphism is unitary (and is also a bijective function).
Example. Let ![n]() be a positive integer. The category
be a positive integer. The category ![\text{nCob}]() of
of ![n]() –cobordisms is the category whose objects are
–cobordisms is the category whose objects are ![n-1]() -dimensional compact manifolds and whose morphisms
-dimensional compact manifolds and whose morphisms ![f : M \to N]() are diffeomorphism classes of
are diffeomorphism classes of ![n]() -dimensional manifolds with boundary the disjoint union
-dimensional manifolds with boundary the disjoint union ![M \sqcup N]() . Composition in this category is defined by “sewing together” two manifolds at a common boundary component. (There are some subtleties here about maintaining a manifold structure when doing this that we will ignore completely.)
. Composition in this category is defined by “sewing together” two manifolds at a common boundary component. (There are some subtleties here about maintaining a manifold structure when doing this that we will ignore completely.)
![\text{nCob}]() is a dagger category with the dagger given by switching the role of
is a dagger category with the dagger given by switching the role of ![M]() and
and ![N]() ; in other words, “turning cobordisms around.”
; in other words, “turning cobordisms around.”
Heuristically speaking, the morphisms in ![\text{nCob}]() describe time evolution between
describe time evolution between ![n-1]() -dimensional “spaces,” with the cobordisms describing
-dimensional “spaces,” with the cobordisms describing ![n]() -dimensional “spacetimes.” (To make the connection to general relativity closer we should require, say, a Lorentzian structure on the cobordisms such that the boundary is a spacelike slice.)
-dimensional “spacetimes.” (To make the connection to general relativity closer we should require, say, a Lorentzian structure on the cobordisms such that the boundary is a spacelike slice.) ![\text{nCob}]() is of fundamental importance to the subject of topological quantum field theory, which is roughly speaking the study of certain kinds of functors
is of fundamental importance to the subject of topological quantum field theory, which is roughly speaking the study of certain kinds of functors ![\text{nCob} \to \text{Vect}]() . A unitary TQFT is a certain kind of dagger functor
. A unitary TQFT is a certain kind of dagger functor ![\text{nCob} \to \text{Hilb}]() , which can be thought of as a “functor from general relativity to quantum mechanics.” For an elaboration on this point of view, see Baez’s Physics, Topology, Logic, and Computation: a Rosetta Stone.
, which can be thought of as a “functor from general relativity to quantum mechanics.” For an elaboration on this point of view, see Baez’s Physics, Topology, Logic, and Computation: a Rosetta Stone.
Example. Let ![C]() be any category which admits finite pullbacks. The category
be any category which admits finite pullbacks. The category ![\text{Span}(C)]() of spans in
of spans in ![C]() is the category whose objects are those of
is the category whose objects are those of ![C]() and whose morphisms
and whose morphisms ![f : a \to b]() are diagrams
are diagrams ![a \leftarrow c \to b]() with composition defined by pullback. Given any span its dagger is simply obtained by switching
with composition defined by pullback. Given any span its dagger is simply obtained by switching ![a]() and
and ![b]() .
.
Spans of sets generalize relations in that they allow “multiple arrows” between an element of ![a]() and an element of
and an element of ![b]() . They also generalize cobordisms, since one can think of a cobordism as a cospan
. They also generalize cobordisms, since one can think of a cobordism as a cospan ![a \to c \rightarrow b]() where the two arrows are the two inclusions of the boundary components into the cobordism. For more about spans, see this page by Baez, which contains slides for a talk as well as references. The tale of groupidification is also relevant.
where the two arrows are the two inclusions of the boundary components into the cobordism. For more about spans, see this page by Baez, which contains slides for a talk as well as references. The tale of groupidification is also relevant.
But let’s return to Hilbert spaces for the time being. Given that we can define unitary maps using only the adjoint, and unitary maps are the isomorphisms preserving the inner products, it seems that the adjoint already captures the inner product on a Hilbert space. This is in fact true.
We first need some notation. In ![\text{Hilb}]() , there is a distinguished object
, there is a distinguished object ![1]() , the one-dimensional Hilbert space
, the one-dimensional Hilbert space ![\mathbb{C}]() . This object represents the obvious forgetful functor to
. This object represents the obvious forgetful functor to ![\text{Set}]() in that
in that ![\text{Hom}(1, H)]() can be canonically identified with the vectors in
can be canonically identified with the vectors in ![H]() . Thus we may think of vectors in
. Thus we may think of vectors in ![H]() as morphisms
as morphisms ![1 \to H]() .
.
Proposition: Let ![v, w : 1 \to H]() be vectors. Then
be vectors. Then ![\langle w, v \rangle = w^{\dagger} v]() .
.
Proof. By definition, ![w^{\dagger}]() is the unique operator
is the unique operator ![H \to 1]() satisfying
satisfying
![\displaystyle \langle w, v \rangle_H = \langle 1, w^{\dagger} v \rangle_1]() .
.
Since ![w^{\dagger} v]() is a morphism
is a morphism ![1 \to 1]() , it is just a scalar, so
, it is just a scalar, so ![\langle 1, w^{\dagger} v \rangle_1 = w^{\dagger} v]() and the conclusion follows.
and the conclusion follows. ![\Box]()
In any dagger category ![C]() with a distinguished object
with a distinguished object ![1 \in C]() (usually the identity object of a monoidal operation on
(usually the identity object of a monoidal operation on ![C]() making it a dagger monoidal category) we may therefore define inner products of morphisms
making it a dagger monoidal category) we may therefore define inner products of morphisms ![1 \to c]() taking values in
taking values in ![\text{End}(1)]() , and this inner product satisfies
, and this inner product satisfies ![w^{\dagger} fv = (f^{\dagger} w)^{\dagger} v]() , so the dagger behaves the same way with respect to it as the adjoint does for Hilbert spaces. Moreover, among the isomorphisms in
, so the dagger behaves the same way with respect to it as the adjoint does for Hilbert spaces. Moreover, among the isomorphisms in ![C]() we can distinguish the unitary isomorphisms because they preserve inner products.
we can distinguish the unitary isomorphisms because they preserve inner products.
Example. In ![\text{Rel}]() , a morphism
, a morphism ![1 \to X]() is a subset of
is a subset of ![X]() , so the functor
, so the functor ![\text{Hom}(1, X)]() sends a set to its collection of subsets and sends a relation
sends a set to its collection of subsets and sends a relation ![R : X \to Y]() to the function
to the function
![\displaystyle R(S) = \{ y \in Y : \exists x \in S : xR y \}]() .
.
(These functions are precisely the functions ![2^X \to 2^Y]() which preserve arbitrary unions.) If
which preserve arbitrary unions.) If ![v, w : 1 \to X]() are two subsets, then
are two subsets, then ![w^{\dagger} v : 1 \to 1]() is one of the two possible subsets of
is one of the two possible subsets of ![\{ 1 \}]() , the empty set and the entire set; it is empty if
, the empty set and the entire set; it is empty if ![w, v]() are disjoint and the entire set otherwise. Then the relation
are disjoint and the entire set otherwise. Then the relation ![w^{\dagger} Rv = (R^{\dagger} w)^{\dagger} v]() when restricted to one-element subsets
when restricted to one-element subsets ![v, w]() says precisely that
says precisely that ![xRy \Leftrightarrow yR^{\dagger} x]() .
.
Quantum weirdness is not so weird
It turns out that some important quantum phenomena, such as quantum teleportation, can be described in an abstract framework based on dagger categories. More precisely, we need dagger compact categories, which are dagger categories equipped with extra structure generalizing the tensor product and dual of Hilbert spaces. The nLab page on this subject has a nice list of references.
This suggests that part of the difference between classical and quantum mechanics boils down to the difference between dagger compact categories and a category like ![\text{Set}]() . A basic such difference is that in a dagger category, the two representable functors
. A basic such difference is that in a dagger category, the two representable functors ![\text{Hom}(c, -)]() and
and ![\text{Hom}(-, c)]() are canonically (contravariantly) isomorphic, the isomorphism provided by the dagger operation. (A unitary isomorphism is then precisely an isomorphism which preserves both representable functors and which also preserves this identification between them.) This is very far from the case in a more classical category like
are canonically (contravariantly) isomorphic, the isomorphism provided by the dagger operation. (A unitary isomorphism is then precisely an isomorphism which preserves both representable functors and which also preserves this identification between them.) This is very far from the case in a more classical category like ![\text{Set}]() .
.
Replacing ![\text{Set}]() with
with ![\text{Rel}]() already helps a great deal. Since relations behave like nondeterministic functions, they are morally much more closely related to linear operators between vector spaces than to (deterministic) functions between sets. In some sense they already are linear operators: it is possible to think of relations as being matrices over the truth semiring
already helps a great deal. Since relations behave like nondeterministic functions, they are morally much more closely related to linear operators between vector spaces than to (deterministic) functions between sets. In some sense they already are linear operators: it is possible to think of relations as being matrices over the truth semiring ![\text{End}(1) = \{ \emptyset, \{ 1 \} \}]() with addition defined by union and multiplication defined by intersection. For the special case of relations between finite sets, this is abstractly because
with addition defined by union and multiplication defined by intersection. For the special case of relations between finite sets, this is abstractly because ![\text{Rel}]() admits finite biproducts (given by the disjoint union) and every finite set is a biproduct of copies of
admits finite biproducts (given by the disjoint union) and every finite set is a biproduct of copies of ![1]() .
.
![\text{Rel}]() admits a monoidal operation given on sets by the Cartesian product. The fact that this is not the categorical product is reflected in the fact that “entangled states” exist: namely there are subsets of a Cartesian product
admits a monoidal operation given on sets by the Cartesian product. The fact that this is not the categorical product is reflected in the fact that “entangled states” exist: namely there are subsets of a Cartesian product ![X \times Y]() which cannot be obtained by taking the product of a subset of
which cannot be obtained by taking the product of a subset of ![X]() with a subset of
with a subset of ![Y]() .
. ![\text{Rel}]() further admits an internal hom
further admits an internal hom ![X \Rightarrow Y]() which is also given on sets by the Cartesian product (but it is contravariant in the first variable; remember that the underlying set here is
which is also given on sets by the Cartesian product (but it is contravariant in the first variable; remember that the underlying set here is ![\text{Hom}(1, -)]() , so we get the set of subsets of the Cartesian product as we should), and the tensor-hom adjunction
, so we get the set of subsets of the Cartesian product as we should), and the tensor-hom adjunction
![\displaystyle \text{Hom}(X \otimes Y, Z) \cong \text{Hom}(X, Y \Rightarrow Z)]()
holds, making ![\text{Rel}]() a closed monoidal category and in fact a dagger compact category.
a closed monoidal category and in fact a dagger compact category.
There is a lot more to say here, but it will have to wait for later posts.


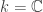

 (linearity in the second argument),
(linearity in the second argument),
 (conjugate symmetry; this implies conjugate linearity in the first argument),
(conjugate symmetry; this implies conjugate linearity in the first argument),
 and
and  (positive-definiteness).
(positive-definiteness).
















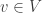






















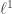





















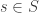




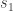
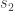


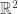







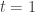


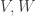











 ), and
), and
 for all
for all  ).
).



















 .
.













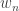
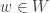










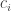
























































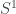
![H = L^2([-\pi, \pi])](http://s0.wp.com/latex.php?latex=H+%3D+L%5E2%28%5B-%5Cpi%2C+%5Cpi%5D%29&bg=ffffff&fg=333333&s=0&c=20201002)


![C([-\pi, \pi])](http://s0.wp.com/latex.php?latex=C%28%5B-%5Cpi%2C+%5Cpi%5D%29&bg=ffffff&fg=333333&s=0&c=20201002)

![L^2([-\pi, \pi])](http://s0.wp.com/latex.php?latex=L%5E2%28%5B-%5Cpi%2C+%5Cpi%5D%29&bg=ffffff&fg=333333&s=0&c=20201002)











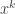











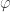















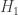

















 ,
,
 (
( a scalar),
a scalar),
 ,
,
 .
.

 ,
,
 .
.